I’m a multi-skilled IT professional with a good all-round supervisory and technical expertise. Extensive, 20+ years of professional experience in software development allowed me to investigate computer science and software engineering inside out. During these years I built up a solid base of design patterns, software architectures and programming languages such as C/C++, Golang, Java, Python, SQL, Assembly (and many others). I worked on mission-critical and multi-channel applications, applying distributed computing, messaging, image/data processing and computer graphics techniques. I faced both architecture design and systems rearchitecting, microservices introduction and technology migration as well as company wide adoption of new technologies/methodologies multiple times.
As an entrepreneur I have built and grown teams and development organizations from the ground up (internal/out sourced/at customer site) focusing on software engineering
methodologies as well as recruiting, budget/financial control and operations support.
I am particularly interested in software testing methodologies, software quality metrics
and tools to make software development faster and better.
Currently leading the Italian development team for ScientiaMobile Inc, a Reston (US) based startup focused on image optimizing CDN and mobile detection technologies and services. Born in Dearborn Michigan and living in Italy since many years now I speak fluently both English and Italian, studied French and learned some Russian while working for some time for a Olivetti/Aeroflot project.
Tiagra rear derailleur is often mounted on gravel bikes but I did not like its limit to 34 maximum cog size. My hackers attitude comes out in these situations (and I don’t care breaking the component warranty) so I decided to modify the derailleur to hold larger cogs.
The problem is that the B-Screw is short and won’t allow you to increase the distanze between the lower cogs from the upper cassette. While some tutorial suggest to put a longer b-screw, I tried what can be seen below :
I used a chain pin and insert it to make the mechanical stop longer. Some thread blocker or resin to keep it still and you’re set.
Friday for Future is running and I feel the need of making sure (firstly to myself) that the process that will bring us totally away from fossil fuel consumption is possible, maybe long, but possible.
Decarbonization (this is the name given to the biggest revamping project in the world) is possible; will require money and time; will require the mutual work of Politics, Science and Industry toward the goals of :
producing electricity totally from renewable sources, decentralize prodution
reducing the energy consumption in all areas were this is possible
decentralize smart grid and electricity storage development
substitute direct fossil fuel consumption with renewable alternatives
stop deforestation process
substitute fossil fuel derived products with fossil derived recycled ones (or carbon free ones if possible)
100 % recycle, waste to energy for the non recyclable
Ambitious plan ? I think this is the biggest revamping project you can immagine and it is already running but I think that the message we all sent last last friday is that we need to ‘deliver’ sooner 🙂
Producing electricity totaly from renewable sources
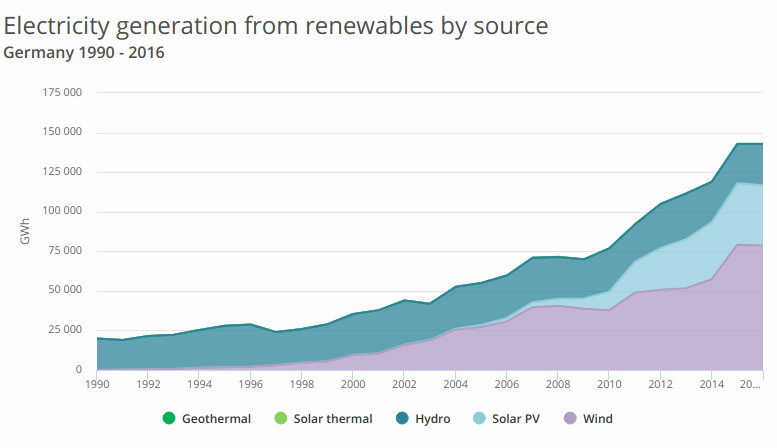
48 % of CO2 is emitted producing heat or electricity. Many countries are already active in the area of producing electricity from renewables, take Germany for example. 7 year ago (just after fukushima) Germany started phase out of nuclear power by incrementing the share of energy produced by renewables. Some data :
In 1 year Germany increased production from wind energ for example by 20 GWh. Continue this for 10 years and your reach more than half the whole country energy requirements. In fact Germany has also started a plan for removing coal in energy production.
In the first 6 months of 2019 Germany has produced more energy from renewables than from fossile/nuclear : here for some references.
Energy efficency
Again from Germany, a national plan to increase the efficency of systems in all areas which is estimating to produce a saving of 12 to 20% over 2020. Reducing the current energy footprint is fundamental for allowing new segments of activities to start using clean energy (think at electrical traction in automotive which is going to increase national demand)
Decentralize smart grid and electricity storage development
The example here comes form Australia were private energy company GreenSync is stimulating customers to setup local electricity storage to be used when there is shortage of power on the grid. Customers are being paid for the storage. For reason not known to me the biggest development in decentralized grid and storage is taking place in Australia and Japan.
Substitute direct fossil fuel consumption with renewable alternatives, limit impatc of direct CO2 emission
This is probably the biggest task in the project because it is spread over a tens of different segments which need to be revamped to achieve the goal :
Road Transportation : around 15% of total CO2 emissions. Redesigning this segment is going to be one of most serious tasks : cars and trucks make up 1/3 of the co2 emissions in countries like US and it is mostly a consumer segment. Battery powered electric cars, pickups and trucks seems to be the directions with Tesla, the real game changer, paving the road. All automotive industry is trying to catchup. 44 Billion investments announces by Volkswagen group over the next 5 years.
Agricolture : How much CO2 is produced by agricolture is the most controversial issue with estimates ranging from 13% of total CO2 emissions to 18% on fao docs, up to 51% including the effect of not having forests where we make food for cows, pigs and chicken. These comes mainly from Cattle belching (CH4) and the addition of natural or synthetic fertilizers and wastes to soils. Here the only possible change is reducing the use of fertilizers and reduce cattle breeding by eating less meat. Read Jonathan Safran Foer book if you want to dig into this more.
Maritime Transportation : 5% of total CO2 emissions, The world’s merchant fleet consists of around 100,000 ships and these are estimated to consume 250 million tonnes of bunker fuel annually. Just one Capesize Bulk Carrier or Bulker can use 40 metric tonnes or fuel or more a day leading to an annual fuel consumption of approximately 10,400 tonnes. This results in the emission of around 32,988 tonnes of CO2 and 959 tonnes of SOx or more. This is just from one ship. Still no real prototypes afaik in this area but good project and potential around with project like Acquarius.
Air Transportation : 2% to 3.5% of total CO2 emissions . Various activities undergoing reduction of carbon footprint in aviation.
Substitute fossil fuel derived products with fossil derived recycled ones (or carbon free ones if possible)
This is probably the biggest task in the project because it is spread over a tens of different segments which need to be revamped to achieve the goal :
Plastics
Lubricants
Process Chemicals
Carpeting
Pharmaceuticals
Rubber Goods
Adhesives
Cosmetics
Footwear
Paints
Detergents
Inks
Sealants
Fragrances
Solvents
Caulking
Compounds
Fertilizers
Fibers
Tires
This point will require a complete structured analysis by its own. International energy agency dedicates a complete section on petrochemicals. They are not easy to replace : recycle will be the solution while Science and Industry find better substitutes.
I’ll stop here at least for now : the message I’m trying to share is that the matter is highly complex and cannot be simplified by just switching off air conditioning or doing these kind of things.
ALL activities have to be done at the same time (thanks Greta for having said this) and Politics IS the driver for all of them.
I think this book is full of valuable thoughts that I would like to recap in this post :
A broken window. One broken window, left unrepaired for any substantial length of time, instills in the inhabitants of the building a sense of abandonment—a sense that the powers that be don’t care about the building. So another window gets broken. People start littering. Graffiti appears. Serious structural damage begins. In a relatively short space of time, the building becomes damaged beyond the owner’s desire to fix it, and the sense of abandonment becomes reality.
How often this applies to software : you can have the best design guidelines but leaving a broken windows (bad design, wrong decisions, poor code) will slowly propagate that error to all the new code written.
Know when to stop
In some ways, programming is like painting. You start with a blank canvas and certain basic raw materials. You use a combination of science, art, and craft to determine what to do with them. You sketch out an overall shape, paint the underlying environment, then fill in the details. You constantly step back with a critical eye to view what you’ve done. Every now and then you’ll throw a canvas away and start again. But artists will tell you that all the hard work is ruined if you don’t know when to stop. If you add layer upon layer, detail over detail, the painting becomes lost in the paint.
I read this as don’t over engineer : let your code do the jobs for some time, don’t over refine.
Dry (Don’t Repeat Yourself)
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.
We all know this right ? But it is not a matter od duplicating code : it is about duplicating knowledge.
Orthogonality
In computing, the term has come to signify a kind of independence or decoupling. Two or more things are orthogonal if changes in one do not affect any of the others. In a well-designed system, the database code will be orthogonal to the user interface: you can change the interface without affecting the database, and swap databases without changing the interface.
You are familiar with orthgonality ( modular, component-based, and layered are synonyms). I read this as : think at your module/component as a service that exposes an API to users :
efficient development (no one is waiting for now one else for stuff to be done)
easy to test : orthogonal systems can be tested independently
Since end of 2016 the European Parliament has filed a proposal for a directive in the area of digital markets and copyrights. As part of this proposal the Article 13 introduces a new concept :
Internet platforms hosting “large amounts” of user-uploaded content must monitor user behavior and filter their contributions to identify and prevent copyright infringement.
As you may imagine this changes the game pretty much.
Let’s make an example : a rightholder of music rights may ask platforms like www.soundcloud.com (Germany) to keep a look over a set of their works. Soundcloud will have to start monitoring all uploads to make sure that those materials are not uploaded by anyone on their platform.
Impact of this regulation, if it is going to pass, will be pretty strong on the EU contries economy. Let’s try to put down some points :
Putting all the control burden on internet platforms hosting contents will probably result in :
being much more difficult for EU companies to compete with US/Asia content providers
get-away from EU countries for all new startups and existing companies in order to not have to comply with regulation
Filter technology is too vast and complicated to be approached by each and single content provider : hundreds of rightholders requiring control over multiple sets of data ( text, images, audio, video, music score, software code ) will generate the need of content check providers that will de facto have censorship power .
Guilty until proven innocent paradigma : if a filter erroneously blocks legal content it will be up to the content owner fight to make his content reinstated
False positives : as in all automated checking procedures the number of false positives could be extremely high resulting in a limitation of freedom of expression
Many campaigns around this can be found :
Save Your Internet: “Stand up and ask Europe to protect Your Internet” (offers contact-your-MEP tool)
Say No to Online Censorship by the Civil Liberties Union for Europe: “Act now! It’s about our freedom to speak. It’s about censorship.” (offers email-your-MEP tool)
#SaveTheMeme,referring to parodies and other expressions of web culture that may be removed by such filtering technology
Create•Refresh: “These changes put the power of small, independent creators in jeopardy. Creative expression will effectively be censored, leaving only the bigger, more established players protected. Many of the sites that we use every day for information or entertainment may cease to exist.”
Writing varnish modules is pretty well documented by the standard varnish documentation, tutorials and thanks to valuable work from other people here . There are some areas I felt the need to be further clarified and this post tries to do that.
Allocating memory inside a vmod is tricky if you need to free it when the current Request is destroyed. Here are some ways :
per request memory allocation i.e. scope is the request lifetime so memory will be freed when the request is destroyed) :
This is a per worker thread memory space allocation, no free necessary as data is removed when the request is detroyed. Ex :
VCL_STRINGvmod_hello(conststructvrt_ctx*ctx,VCL_STRINGname){char*p;unsignedu,v;u=WS_Reserve(ctx->ws,0);/*Reservesomeworkspace*/p=ctx->ws->f;/*Frontofworkspacearea*/v=snprintf(p,u,"Hello, %s",name);v++;if(v>u){/*Nospace,resetandleave*/WS_Release(ctx->ws,0);return(NULL);}/*Updateworkspacewithwhatwe've used */WS_Release(ctx->ws,v);return(p);}
Data is allocated starting with 64k and then when needed in 4k chunks in the cts->ws area. No varnish imposed limit.
(since varnish 4.0 up) Private Pointers: a way to have multi-scoped private data per each VCL, TASK. You may access private data either as passed on the VCL function signature or by calling directly VRT_priv_task(ctx, “name”) for example to obtain a per request place to hold :
free function
pointer to allocated data
This method is very interesting if you need a cleanup function to be called when the varnish request is destroyed.